Redirects are a normal part of web infrastructure. They help enforce HTTPS, consolidate domains, preserve links during migrations and route users to the correct content. Problems arise when redirects are layered incorrectly or configured without full visibility into the request path.
Two of the most common misconfigurations are the redirect chain and the redirect loop. While they may appear similar at first glance, they behave very differently and require different approaches to resolve.
This guide explains what they are, how they happen and how they affect performance and SEO. Most importantly, it shows how to fix redirect chains and resolve redirect loops in production environments.
What is a redirect chain?
A redirect chain occurs when one URL redirects to another URL, which then redirects again before reaching a final destination.

Instead of redirecting directly from A to D, the request must pass through one or more intermediate steps. When multiple redirects stack on top of each other, you end up with redirect chains.
Why redirect chains happen
Redirect chains typically emerge over time rather than being intentionally designed. They often result from:
- Multiple site or content migrations.
- Layered HTTPS and domain normalization rules.
- CMS plugins redirects layering ontop of other redirect rules.
- Conflicting CDN and origin rules.
- Legacy URLs that accumulate over time.
Each configuration change may seem correct in isolation. The chain forms when those changes accumulate.
Why redirect chains are a problem
While a short chain of 1-2 redirects may still resolve successfully, longer chains, such as 3+, introduce measurable issues:
- Increased latency for users.
- Increased total response time, affecting website SEO health.
- Complicated debugging during migrations.
- Potential dilution of link equity.
Redirect chains add time to your total response time. Since under 200 ms is ideal, every additional redirect can raise this number.
Even when search engines follow multiple redirects, each hop adds overhead. Over time, this can impact performance and visibility.
What is a redirect loop?
A redirect loop occurs when two or more URLs continuously redirect to each other, preventing the browser from ever reaching a final destination.
If a redirect chain is inefficient but functional, a redirect loop is a hard failure.
For example:
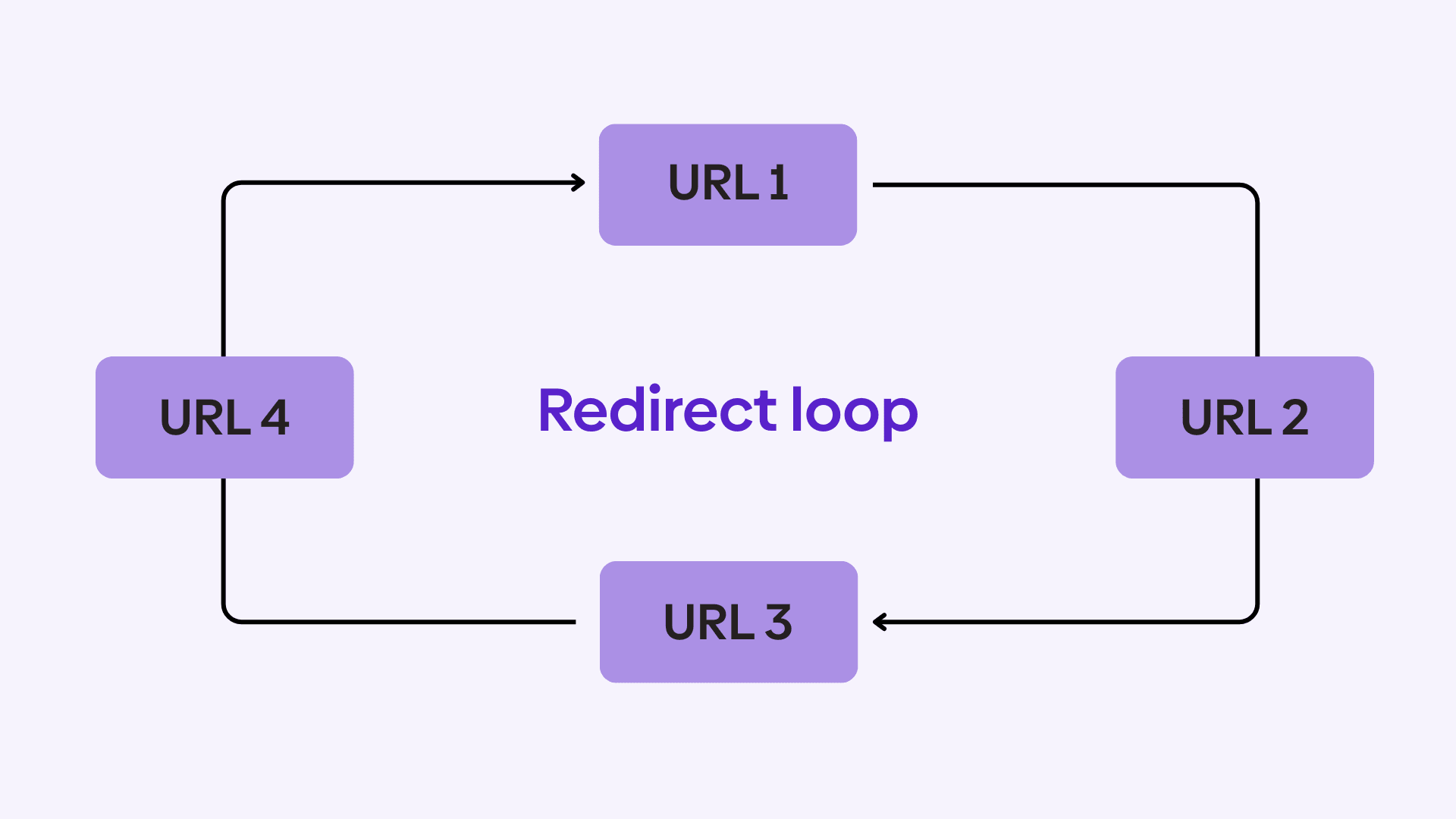
The browser eventually stops and displays an error such as “Too many redirects.”
If you’re asking, what does a redirect loop mean in practical terms, it means the request never resolves. No content loads. The browser aborts the process after hitting its redirect limit.
Why do redirect loops happen?
A redirect loop is usually caused by conflicting logic across different infrastructure layers. Common causes include:
- HTTPS enforcement at both CDN and origin.
- www to non-www redirects are configured in multiple places.
- Reverse proxy header misconfiguration.
- Application-level redirects are unaware of upstream routing.
- Mixed environment routing during migrations.
Unlike redirect chains, which can persist unnoticed, redirect loops surface immediately because they break the page entirely.
Redirect chains and loops: what’s the difference?
Although both issues involve multiple redirects, they are structurally different.
A redirect chain eventually resolves. It may pass through several intermediate URLs, but it ultimately lands on a final destination.
A redirect loop never resolves. It cycles endlessly between URLs until the browser stops the request.
From a severity standpoint:
- Redirect chains harm performance and crawl efficiency.
- Redirect loops break accessibility entirely.
Understanding this distinction is critical when diagnosing infrastructure issues.
Common scenarios where redirect chains and loops occur
Redirect chains and loops rarely appear all at once. They usually form gradually, introduced by well-intentioned changes that were never fully consolidated. Certain scenarios make them far more likely.
Most redirect chains and loops are not caused by a single mistake. They are the result of layered changes made over time without a full audit of existing rules. Identifying where redirect logic lives and ensuring it is controlled consistently is the most effective way to prevent them.
Website migrations
Migrations are one of the most common sources of both redirect chains and redirect loops. When a site moves from Domain A to Domain B and later from Domain B to Domain C, existing redirect rules often remain in place.

What began as a correct redirect becomes a redirect chain simply because legacy rules were never consolidated. The correct solution is not to stack additional redirects, but to update earlier rules so both A and B point directly to C.
Migrations can also cause redirect loops. Loops can occur when multiple systems attempt to enforce HTTPS or canonical hostnames simultaneously. Without clearly defining which layer owns the redirect logic, conflicts become inevitable.
Conflicting redirect systems
Modern websites often manage redirects in several places at once: DNS providers, CDNs, load balancers, web servers and CMS plugins. Each system may independently enforce rules such as HTTPS, trailing slash normalization or www to non-www consolidation.
Problems arise when these systems are unaware of each other.
For example, a CDN may redirect HTTP to HTTPS while the origin server attempts to perform the same enforcement again. If headers are not preserved correctly, the origin may believe the request is still HTTP and trigger another redirect. In some cases, this produces a redirect loop. In others, it quietly introduces a redirect chain.
Redirect management works best when it has a clear owner. Without a single source of truth, duplication and conflict become difficult to avoid.
Moving pages multiple times
Content that is frequently reorganized can accumulate redirect chains over time. A page may move from one path to another, then to a new subdirectory and later to a different subdomain. Each move introduces a new redirect.
If older rules are left intact, users may be routed through multiple intermediate URLs before reaching the final version. What began as a simple change becomes a layered redirect structure that slows resolution and complicates maintenance.
The long-term solution is strategic URL planning. When a page moves, older redirects should be updated to point directly to the newest destination, bypassing intermediate steps.
Subtle configuration errors
Some of the most frustrating redirect loops stem from small configuration details rather than large architectural decisions.
A common example occurs during HTTP to HTTPS transitions. If an HTTP request redirects to HTTPS at one layer, but another layer mistakenly routes HTTPS traffic back to HTTP, the request can enter a loop.
Trailing slash normalization can create similar problems. If both /page and /page/ are treated as valid but competing canonical versions, redirect rules attempting to enforce one format may conflict with rules attempting to enforce the other.
Host normalization can also introduce loops. Host normalization refers to enforcing a single canonical hostname for your site, typically either www.example.com or example.com (the apex domain). This is usually done for SEO consistency, cookie scoping or infrastructure simplicity.
Problems occur when different layers enforce different versions. For example, a CDN may redirect all traffic to www.example.com, while the origin server is configured to redirect everything to example.com. When a user requests example.com, the CDN sends it to www.example.com. The origin then sees www.example.com and redirects it back to example.com. The request cycles between the two systems indefinitely, resulting in a redirect loop.
These loops often happen during migrations when host normalization rules are configured in multiple places, such as at the load balancer, CDN and application layer, without clearly defining which layer owns canonicalization. To prevent this, choose one canonical hostname and enforce it in a single, authoritative layer.
SEO and performance impact
Search engines are capable of following multiple redirects, but excessive redirect chains increase crawl cost and reduce efficiency. Long chains may also slow down page load time, indirectly affecting Core Web Vitals.
A good goal for total response time is 200 ms or less. Adding delays to your page load time gives your website visitors a bad user experience and may affect whether they engage with your site.
Redirect loops, on the other hand, prevent indexing entirely. If search engines cannot reach the final content, the page will not be crawled or ranked.
For sites undergoing migrations or structural updates, monitoring redirect chains and loops is essential to preserve traffic and ensure content remains accessible.
How to find redirect loops and redirect chains.
Before fixing anything, you need visibility.
A redirect chain can only be diagnosed by inspecting every hop in the redirect path. Browsers may hide intermediate steps unless developer tools are used.
A redirect loop is more obvious because it triggers browser errors. However, identifying the exact rule causing the loop requires inspecting server responses and headers.
Specialized redirect inspection tools such as urllo's free redirect checker or Semrush Site Audit can display full chains, status codes (301, 302, 307, 308) and final destinations. This visibility is essential for safely removing duplicate or conflicting rules.
How to fix redirect chains
A redirect chain is not usually a configuration “bug.” It is an accumulation problem. Over time, redirects are added but rarely consolidated. Fixing a chain requires reducing it to a single direct hop.
The goal is simple:
Old URL → Final URL
Not
Old URL → Intermediate URL → Another URL → Final URL
Step 1: Identify the full redirect path
You cannot fix a chain without seeing every hop.
Inspect the complete redirect flow for affected URLs. You need to know:
- The initial request URL.
- Each intermediate response.
- The status code at each step.
- The final destination.
This must be tested in real conditions, not assumed from configuration files. Many chains exist across layers (CDN + server + CMS), so reviewing only one system is not enough.
Step 2: Determine redirect ownership
Once you see the full chain, determine where each redirect is being issued.
Common layers include:
- CDN rules.
- Load balancer rules.
- Reverse proxy configuration.
- Web server config (Nginx, Apache).
- CMS/plugin redirects.
Redirect chains usually form because different layers are enforcing overlapping behavior.
For example:
CDN forces HTTPSServer enforces non-wwwCMS redirects legacy slug
Each rule makes sense alone. Together, they create a chain.
You must decide which layer should own each type of redirect (protocol, host normalization, path changes). Redirect responsibility should be centralized as much as possible.
Step 3: Collapse the chain
Once ownership is clarified, update older rules to point directly to the final URL.
If your current structure is:
A → B
B → C
Update A so it redirects directly to C. Remove or update legacy references to B.
Do not simply add new redirects on top of existing ones. That is how chains grow.
Step 4: Remove legacy redirects
Chains often include redirects that no longer serve a purpose.
After consolidation:
- Remove redirects that are no longer referenced.
- Eliminate duplicate enforcement rules.
- Archive historical redirect rules instead of leaving them active.
A clean redirect map is easier to maintain and audit.
Step 5: Validate under production conditions
After changes are deployed, test again.
Confirm:
- The original URL resolves to a single redirect.
- The correct status code is returned (typically 301 for permanent moves).
- The final URL returns a 200 OK.
Fixing redirect chains is about simplification. If the path is not linear and direct, it is not finished.
How to fix redirect loops
Redirect loops are different. They are not an accumulation issue; they are a logic conflict.
A loop means two systems disagree about what the correct state of the request is.
The goal is not consolidation.The goal is conflict resolution.
Step 1: Identify the looping pattern
A redirect loop typically looks like:
A → B → A (repeating infinitely)orHTTP → HTTPS → HTTP (repeating infinitely)
Capture the exact pattern. Identify which URL is redirecting back to the previous one.
Loops often surface as:
- ERR_TOO_MANY_REDIRECTS.
- Browser refusing to load the page.
But the browser error is not enough. You must inspect the headers and status codes at each hop.
Step 2: Check protocol enforcement first
Many redirect loops occur during HTTP to HTTPS transitions.
If both the CDN and origin enforce HTTPS, the origin may misinterpret the request if proxy headers are not preserved correctly.
For example:
- CDN receives HTTP, redirects to HTTPS.
- Origin receives HTTPS but thinks it’s HTTP.
- Origin redirects again.
This cycle continues indefinitely.
Verify:
- Whether X-Forwarded-Proto or similar headers are passed correctly.
- Whether only one layer is responsible for protocol enforcement.
Only one system should control HTTP to HTTPS redirection.
Step 3: Check host normalization
Another common loop source is www vs non-www enforcement.
If:
- The CDN forces www.example.com.
- The server forces example.com.
The request will bounce back and forth.
Choose a canonical host and remove conflicting rules elsewhere.
Step 4: Review reverse proxy and header behavior
Reverse proxies and load balancers may rewrite or drop headers.
If your application relies on header detection (e.g., Host, X-Forwarded-Proto) to determine redirect behavior, incorrect forwarding can cause the application to misfire.
Inspect:
- Whether the proxy preserves the original protocol.
- Whether headers are overwritten downstream.
- Whether the application assumes direct connections.
Many loops are caused by incorrect assumptions about the request origin.
Step 5: Eliminate duplicate enforcement rules
Loops almost always occur because two systems are enforcing the same rule.
Common duplication points:
- CDN + origin both enforcing HTTPS.
- Server + CMS plugin both enforcing trailing slash format.
- Load balancer + app both redirecting to canonical host.
Decide where the rule should live. Remove it everywhere else.
Step 6: test in a clean environment
Browsers cache redirects aggressively.
After resolving a loop:
- Clear browser cache.
- Test in an incognito window.
- Use command-line requests to validate raw responses.
- Use a redirect or link checker.
Cached behavior can mask whether the loop has actually been resolved.
Take control of your redirect infrastructure
Redirect chains and redirect loops are rarely the result of a single mistake. They are usually the byproduct of fragmented ownership, rules split across CDNs, servers, CMS plugins and legacy configurations with no unified oversight.
Fixing individual errors is important, but long-term stability requires a centralized approach such as a website redirector. Redirect logic should live in one controlled system, with clear visibility into every rule, every domain and every destination. Without that clarity, chains accumulate quietly and loops appear when systems begin to conflict.
A dedicated redirect management platform like urllo brings that visibility into one place. Instead of relying on scattered configurations across multiple layers, teams can deploy, audit and maintain redirects through a single dashboard. This reduces duplication, eliminates misalignment between systems and makes it easier to consolidate legacy rules before they become performance or SEO liabilities.
Redirects are foundational infrastructure. Managing them intentionally, with the right process and tooling, ensures your website remains fast, accessible and structurally sound as it evolves.
Frequently asked questions about redirect chains and redirect loops
What is the difference between a redirect chain and a redirect loop?
A redirect chain occurs when a URL passes through two or more redirects before reaching its final destination. The request eventually resolves, but it takes unnecessary steps to get there.
A redirect loop, by contrast, never resolves. Two or more URLs continuously redirect to each other, preventing the browser from loading the final page.
Are redirect chains bad for SEO?
Short redirect chains may still resolve, but longer chains increase latency and reduce crawl efficiency. While search engines can follow multiple redirects, the best practice is to keep them to a single direct hop. Larger sites, especially those with 10,000+ pages, are more likely to waste crawl budget if chains accumulate.
Can redirect loops prevent indexing?
Yes. A redirect loop prevents search engines from reaching the final content. If the crawler cannot access a page because it is stuck in a loop, that page cannot be indexed or ranked.
Why do redirect loops often happen after HTTPS migrations?
Redirect loops commonly occur when multiple systems enforce HTTPS simultaneously. For example, a CDN may redirect HTTP to HTTPS, while the origin server attempts to apply the same rule again. If proxy headers are not handled correctly, the origin may misinterpret the request and repeatedly trigger redirects.
How do I find redirect chains on my website?
Redirect chains can only be identified by inspecting the full redirect path of a URL. Browser developer tools, command-line requests or dedicated redirect inspection tools can reveal each intermediate hop and status code. Reviewing configuration files alone is not sufficient, since chains often span multiple infrastructure layers.
Can a CDN cause redirect loops?
Yes. A CDN can introduce redirect loops if it enforces rules that conflict with origin server logic. Common examples include duplicated HTTPS enforcement or host normalization rules. Redirect ownership should be clearly defined to avoid cross-layer conflicts.
How many redirects can Google follow?
Google can follow multiple redirects, but there is a practical limit. Excessive chains reduce crawl efficiency and may delay indexing. Keeping redirects to a single hop provides the most reliable and efficient behavior.
How can I prevent redirect chains and loops?
Preventing issues requires centralized redirect management and regular audits. Redirect logic should have a clearly defined owner and legacy rules should be consolidated during migrations or structural changes. Testing real request behavior after configuration updates is essential to avoid unintended chains or loops.

By Sean Pasemko
SEO & Growth Marketing Specialist
Sean Pasemko is an SEO and growth marketer at urllo, where he works closely with SEO, IT and WebOps teams on redirect management, domain changes and site migrations.
His writing draws on practical experience analyzing redirect behavior, crawl efficiency and long-term site maintenance to help teams avoid common routing and performance issues.